


A Vector Database is a specialized database system designed for efficiently indexing, querying, and retrieving high-dimensional vector data. Those systems enable advanced data analysis and similarity-search operations that extend well beyond the traditional, structured query approach of conventional databases.
Why use a Vector Database?
The data flood is real.
In 2024, we're drowning in unstructured data like images, text, and audio, that don’t fit into neatly organized tables. Still, we need a way to easily tap into the value within this chaos of almost 330 million terabytes of data being created each day.
Traditional databases, even with extensions that provide some vector handling capabilities, struggle with the complexities and demands of high-dimensional vector data.
Handling of vector data is extremely resource-intensive. A traditional vector is around 6Kb. You can see how scaling to millions of vectors can demand substantial system memory and computational resources. Which is at least very challenging for traditional OLTP and OLAP databases to manage.
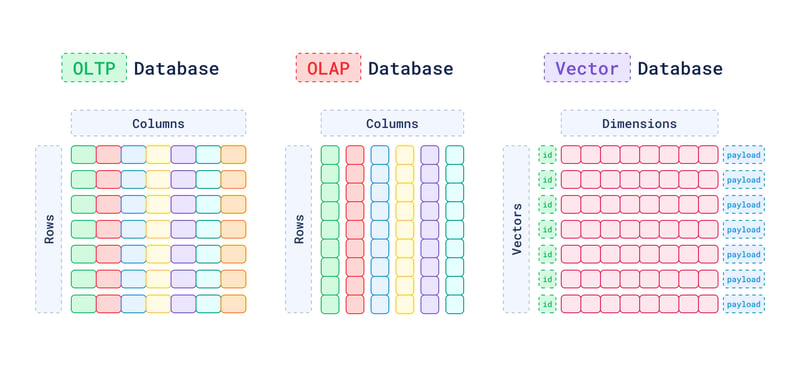
Vector databases allow you to understand the context or conceptual similarity of unstructured data by representing them as vectors, enabling advanced analysis and retrieval based on data similarity.
For example, in recommendation systems, vector databases can analyze user behavior and item characteristics to suggest products or content with a high degree of personal relevance.
In search engines and research databases, they enhance the user experience by providing results that are semantically similar to the query, rather than relying solely on the exact words typed into the search bar.
If you’re new to the vector search space, this article explains the key concepts and relationships that you need to know.
So let's get into it.
What is Vector Data?
To understand vector databases, let's begin by defining what is a 'vector' or 'vector data'.
Vectors are a numerical representation of some type of complex information.
To represent textual data, for example, it will encapsulate the nuances of language, such as semantics and context.
With an image, the vector data encapsulates aspects like color, texture, and shape. The dimensions relate to the complexity and the amount of information each image contains.
Each pixel in an image can be seen as one dimension, as it holds data (like color intensity values for red, green, and blue channels in a color image). So even a small image with thousands of pixels translates to thousands of dimensions.
So from now on, when we talk about high-dimensional data, we mean that the data contains a large number of data points (pixels, features, semantics, syntax).
The creation of vector data (so we can store this high-dimensional data on our vector database) is primarily done through embeddings.
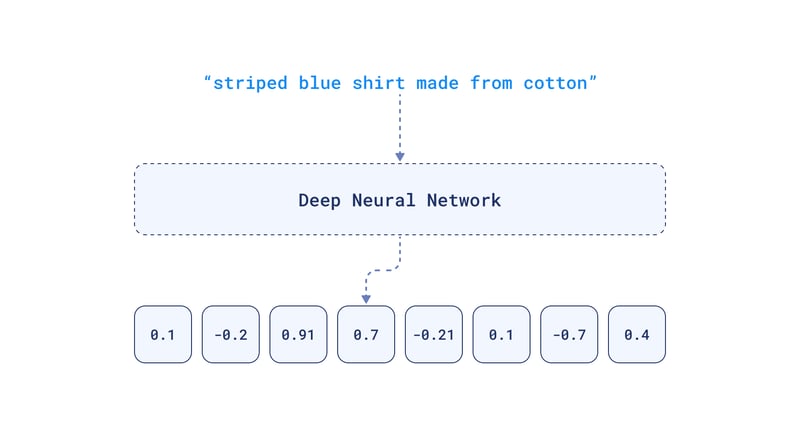
How do Embeddings Work?
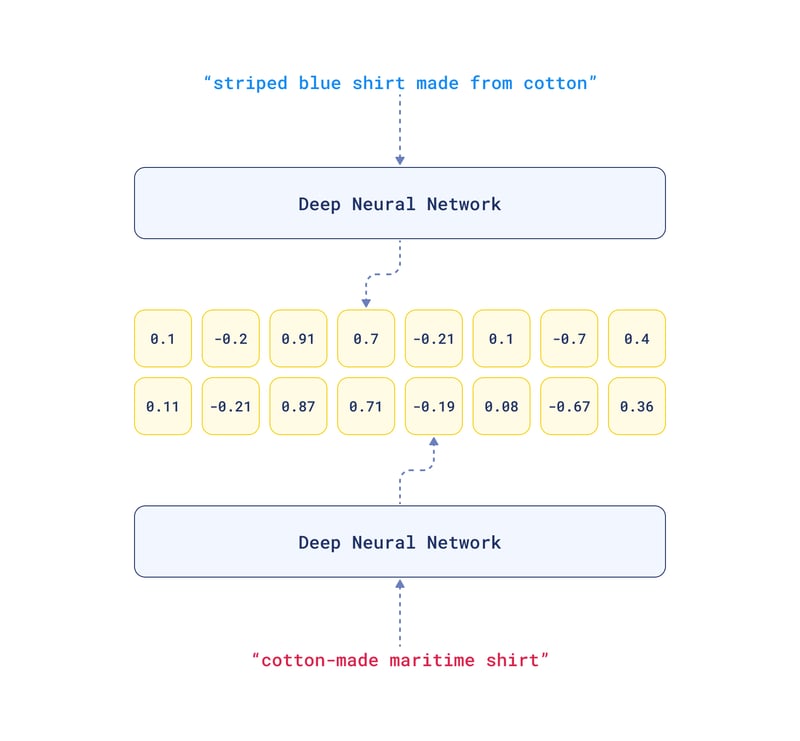
Embeddings translate this high-dimensional data into a more manageable, lower-dimensional vector form that's more suitable for machine learning and data processing applications, typically through neural network models.
In creating dimensions for text, for example, the process involves analyzing the text to capture its linguistic elements.
Transformer-based neural networks like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), are widely used for creating text embeddings.
Each layer extracts different levels of features, such as context, semantics, and syntax.
The final layers of the network condense this information into a vector that is a compact, lower-dimensional representation of the image but still retains the essential information.
Core Functionalities of Vector Databases
What is Indexing?
Have you ever tried to find a specific face in a massive crowd photo? Well, vector databases face a similar challenge when dealing with tons of high-dimensional vectors.
Now, imagine dividing the crowd into smaller groups based on hair color, then eye color, then clothing style. Each layer gets you closer to who you’re looking for. Vector databases use similar multi-layered structures called indexes to organize vectors based on their "likeness."
This way, finding similar images becomes a quick hop across related groups, instead of scanning every picture one by one.
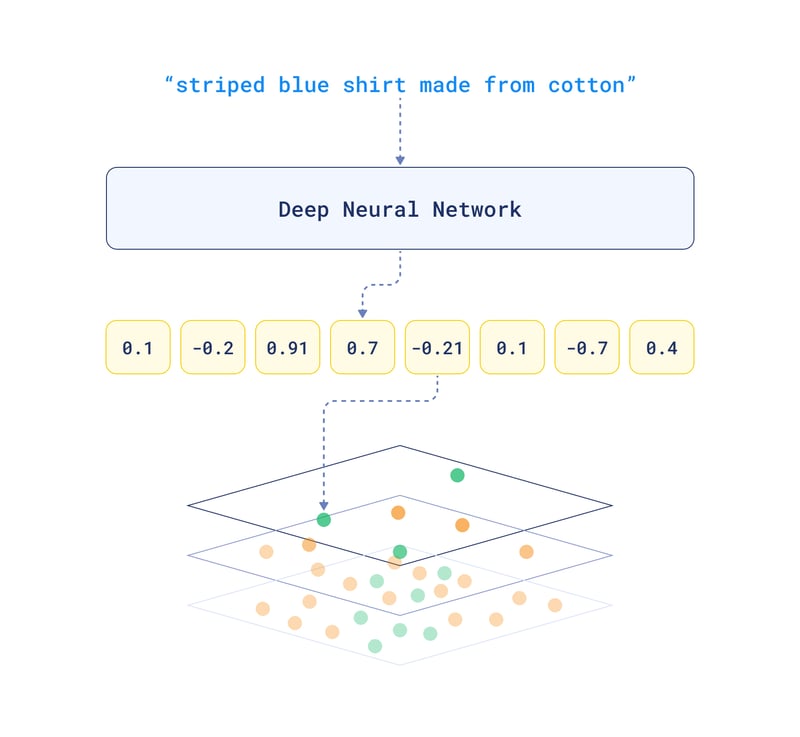
Different indexing methods exist, each with its strengths. HNSW balances speed and accuracy like a well-connected network of shortcuts in the crowd. Others, like IVF or Product Quantization, focus on specific tasks or memory efficiency.
What is Binary Quantization?
Quantization is a technique used for reducing the total size of the database. It works by compressing vectors into a more compact representation at the cost of accuracy.
Binary Quantization is a fast indexing and data compression method used by Qdrant. It supports vector comparisons, which can dramatically speed up query processing times (up to 40x faster!).
Think of each data point as a ruler. Binary quantization splits this ruler in half at a certain point, marking everything above as "1" and everything below as "0". This binarization process results in a string of bits, representing the original vector.
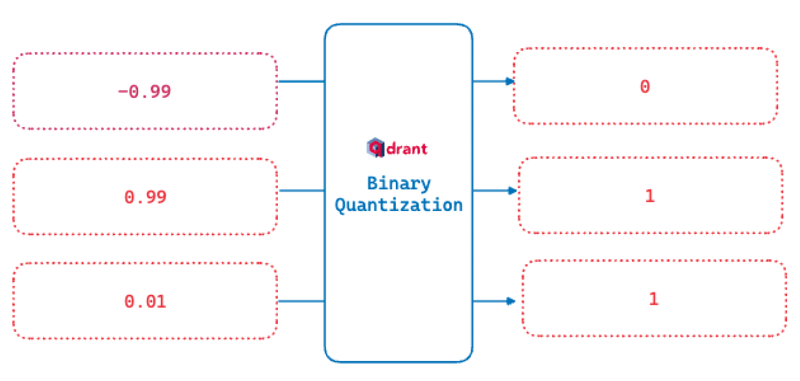
This "quantized" code is much smaller and easier to compare. Especially for OpenAI embeddings, this type of quantization has proven to achieve a massive performance improvement at a lower cost of accuracy.
What is Similarity Search?
Similarity search allows you to search not by keywords but by meaning. This way you can do searches such as similar songs that evoke the same mood, finding images that match your artistic vision, or even exploring emotional patterns in text.
The way it works is, when the user queries the database, this query is also converted into a vector (the query vector). The vector search starts at the top layer of the HNSW index, where the algorithm quickly identifies the area of the graph likely to contain vectors closest to the query vector. The algorithm compares your query vector to all the others, using metrics like "distance" or "similarity" to gauge how close they are.
The search then moves down progressively narrowing down to more closely related vectors. The goal is to narrow down the dataset to the most relevant items. The image below illustrates this.
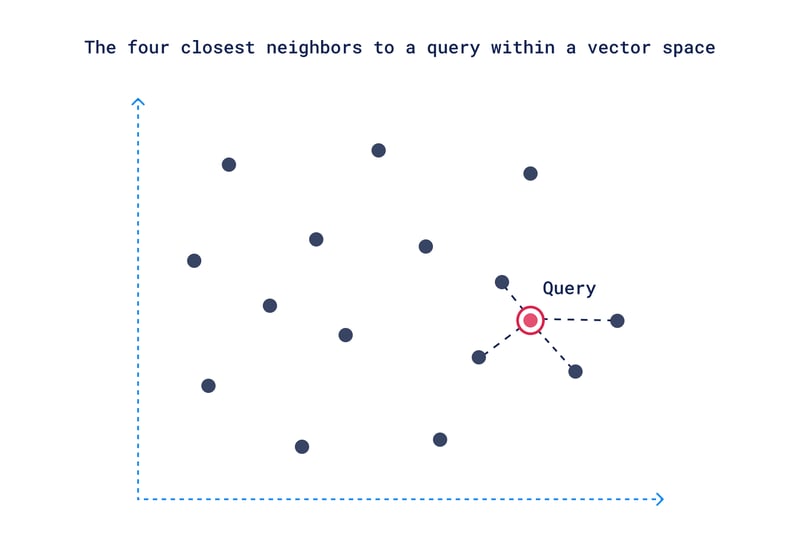
Once the closest vectors are identified at the bottom layer, these points translate back to actual data, like images or music, representing your search results.
Scalability
Vector databases often deal with datasets that comprise billions of high-dimensional vectors. This data isn't just large in volume but also complex in nature, requiring more computing power and memory to process. Scalable systems can handle this increased complexity without performance degradation. This is achieved through a combination of a distributed architecture, dynamic resource allocation, data partitioning, load balancing, and optimization techniques.
Systems like Qdrant, exemplify scalability in vector databases. It leverages Rust's efficiency in memory management and performance, allowing handling of large-scale data with optimized resource usage.
Efficient Query Processing
The key to efficient query processing in these databases is linked to their indexing methods, which enable quick navigation through complex data structures. By mapping and accessing the high-dimensional vector space, HNSW and similar indexing techniques significantly reduce the time needed to locate and retrieve relevant data.
Other techniques like handling computational load and parallel processing are used for performance, especially when managing multiple simultaneous queries. Complementing them, strategic caching is also employed to store frequently accessed data, facilitating a quicker retrieval for subsequent queries.
Using Metadata and Filters
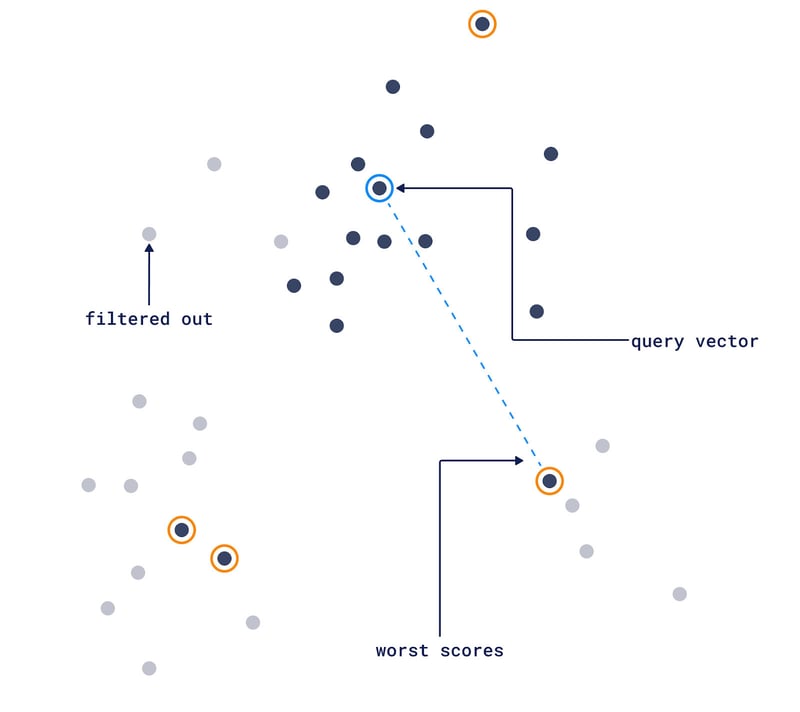
Filters use metadata to refine search queries within the database. For example, in a database containing text documents, a user might want to search for documents not only based on textual similarity but also filter the results by publication date or author.
When a query is made, the system can use both the vector data and the metadata to process the query. In other words, the database doesn’t just look for the closest vectors. It also considers the additional criteria set by the metadata filters, creating a more customizable search experience.
Data Security and Access Control
Vector databases often store sensitive information. This could include personal data in customer databases, confidential images, or proprietary text documents. Ensuring data security means protecting this information from unauthorized access, breaches, and other forms of cyber threats.
At Qdrant, this includes mechanisms such as:
User authentication
Role-based access control
Attribute-based access control
Encryption for data at rest and in transit
Keeping audit trails
Advanced database monitoring and anomaly detection
Architecture of a Vector Database
A vector database is made of multiple different entities and relations. Here's a high-level overview of Qdrant's terminologies and how they fit into the larger picture:
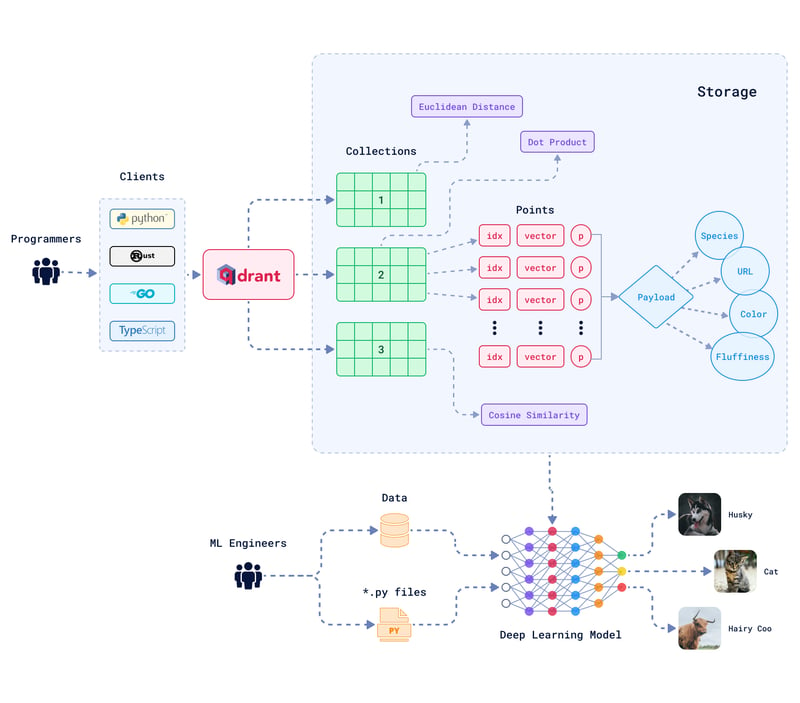
Collections: Collections are a named set of data points, where each point is a vector with an associated payload. All vectors within a collection must have the same dimensionality and be comparable using a single metric.
Distance Metrics: These metrics are used to measure the similarity between vectors. The choice of distance metric is made when creating a collection. It depends on the nature of the vectors and how they were generated, considering the neural network used for the encoding.
Points: Each point consists of a vector and can also include an optional identifier (ID) and payload. The vector represents the high-dimensional data and the payload carries metadata information in a JSON format, giving the data point more context or attributes.
Storage Options: There are two primary storage options. The in-memory storage option keeps all vectors in RAM, which allows for the highest speed in data access since disk access is only required for persistence.
Alternatively, the Memmap storage option creates a virtual address space linked with the file on disk, giving a balance between memory usage and access speed.
Clients: Qdrant supports various programming languages for client interaction, such as Python, Go, Rust, and Typescript. This way developers can connect to and interact with Qdrant using the programming language they prefer.
Vector Database Use Cases
If we had to summarize the use cases for vector databases into a single word, it would be "match". They are great at finding non-obvious ways to correspond or “match” data with a given query. Whether it's through similarity in images, text, user preferences, or patterns in data.
Here are some examples of how to take advantage of using vector databases:
Personalized recommendation systems to analyze and interpret complex user data, such as preferences, behaviors, and interactions. For example, on Spotify, if a user frequently listens to the same song or skips it, the recommendation engine takes note of this to personalize future suggestions.
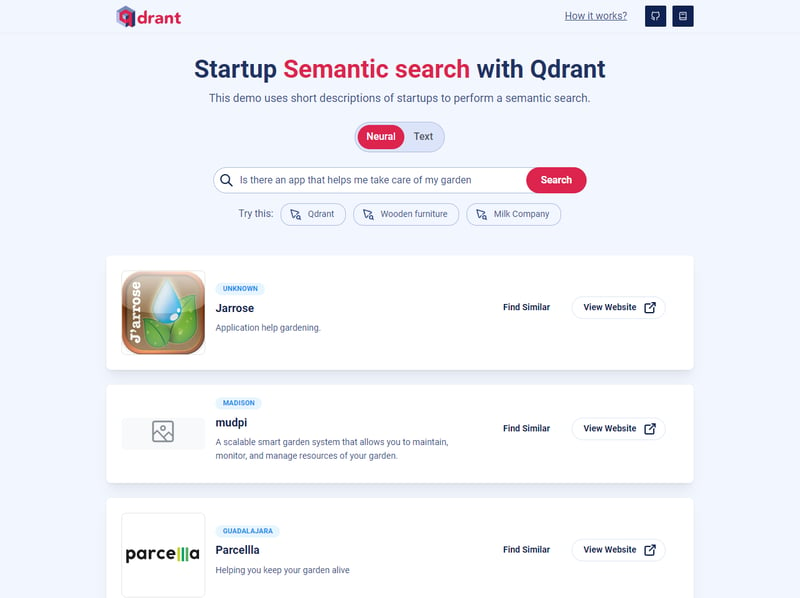
Semantic search allows for systems to be able to capture the deeper semantic meaning of words and text. In modern search engines, if someone searches for "tips for planting in spring," it tries to understand the intent and contextual meaning behind the query. It doesn’t try just matching the words themselves. Here’s an example of a vector search engine for Startups made with Qdrant:
There are many other use cases like for fraud detection and anomaly analysis used in sectors like finance and cybersecurity, to detect anomalies and potential fraud. And Content-Based Image Retrieval (CBIR) for images by comparing vector representations rather than metadata or tags.
Those are just a few examples. The ability of vector databases to “match” data with queries makes them essential for multiple types of applications. Here are some more use case examples you can take a look at.
Starting Your First Vector Database Project
Now that you're familiar with the core concepts around vector databases, it’s time to get our hands dirty. Start by building your own semantic search engine for science fiction books in just about 5 minutes with the help of Qdrant. You can also watch our video tutorial.
Feeling ready to dive into a more complex project? Take the next step and get started building an actual Neural Search Service with a complete API and a dataset.
Let’s get into action!