What are Vector Embeddings?

Attempting at DevRel and trying not to break production. I can build ANYTHING with Python and coffee.
Embeddings are numerical machine learning representations of the semantic of the input data. They capture the meaning of complex, high-dimensional data, like text, images, or audio, into vectors. Enabling algorithms to process and analyze the data more efficiently.
You know when you’re scrolling through your social media feeds and the content just feels incredibly tailored to you? There's the news you care about, followed by a perfect tutorial with your favorite tech stack, and then a meme that makes you laugh so hard you snort.
Or what about how YouTube recommends videos you ended up loving. It’s by creators you've never even heard of and you didn’t even send YouTube a note about your ideal content lineup.
This is the magic of embeddings.
These are the result of deep learning models analyzing the data of your interactions online. From your likes, shares, comments, searches, the kind of content you linger on, and even the content you decide to skip. It also allows the algorithm to predict future content that you are likely to appreciate.
The same embeddings can be repurposed for search, ads, and other features, creating a highly personalized user experience.
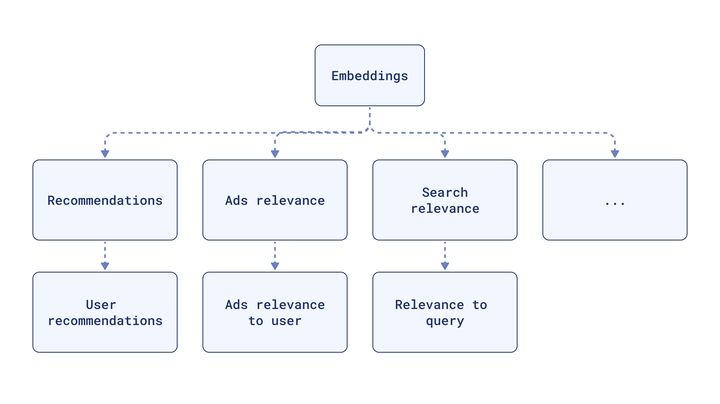
They make high-dimensional data more manageable. This reduces storage requirements, improves computational efficiency, and makes sense of a ton of unstructured data.
Why Use Vector Embeddings?
The nuances of natural language or the hidden meaning in large datasets of images, sounds, or user interactions are hard to fit into a table. Traditional relational databases can't efficiently query most types of data being currently used and produced, making the retrieval of this information very limited.
In the embeddings space, synonyms tend to appear in similar contexts and end up having similar embeddings. The space is a system smart enough to understand that "pretty" and "attractive" are playing for the same team. Without being explicitly told so.
That’s the magic.
At their core, vector embeddings are about semantics. They take the idea that "a word is known by the company it keeps" and apply it on a grand scale.

This capability is crucial for creating search systems, recommendation engines, retrieval augmented generation (RAG) and any application that benefits from a deep understanding of content.
How do embeddings work?
Embeddings are created through neural networks. They capture complex relationships and semantics into dense vectors which are more suitable for machine learning and data processing applications. They can then project these vectors into a proper high-dimensional space, specifically, a Vector Database.
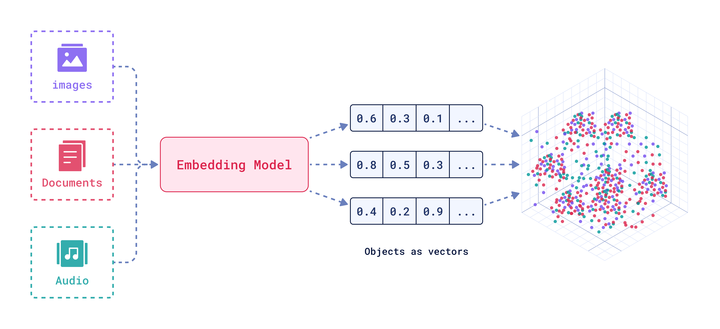
The meaning of a data point is implicitly defined by its position on the vector space. After the vectors are stored, we can use their spatial properties to perform nearest neighbor searches. These searches retrieve semantically similar items based on how close they are in this space.
The quality of the vector representations drives the performance. The embedding model that works best for you depends on your use case.
Creating Vector Embeddings
Embeddings translate the complexities of human language to a format that computers can understand. It uses neural networks to assign numerical values to the input data, in a way that similar data has similar values.
For example, if I want to make my computer understand the word 'right', I can assign a number like 1.3. So when my computer sees 1.3, it sees the word 'right’.
Now I want to make my computer understand the context of the word ‘right’. I can use a two-dimensional vector, such as [1.3, 0.8], to represent 'right'. The first number 1.3 still identifies the word 'right', but the second number 0.8 specifies the context.
We can introduce more dimensions to capture more nuances. For example, a third dimension could represent formality of the word, a fourth could indicate its emotional connotation (positive, neutral, negative), and so on.
The evolution of this concept led to the development of embedding models like Word2Vec and GloVe. They learn to understand the context in which words appear to generate high-dimensional vectors for each word, capturing far more complex properties.
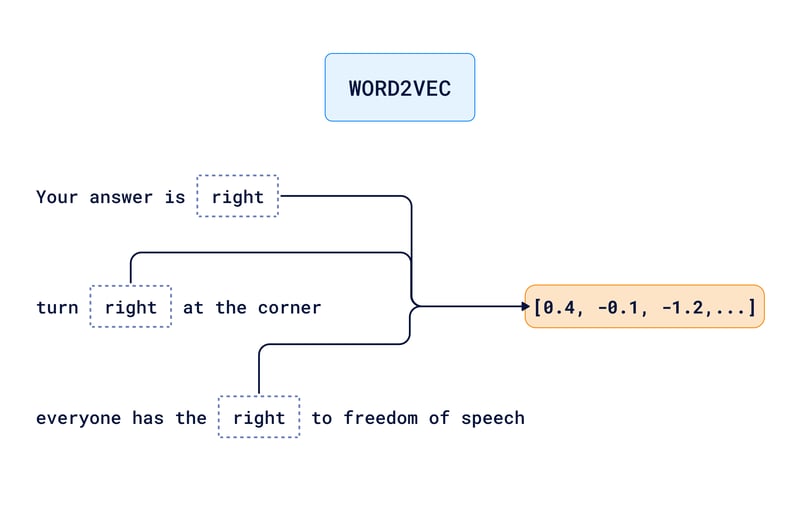
However, these models still have limitations. They generate a single vector per word, based on its usage across texts. This means all the nuances of the word "right" are blended into one vector representation. That is not enough information for computers to fully understand the context.
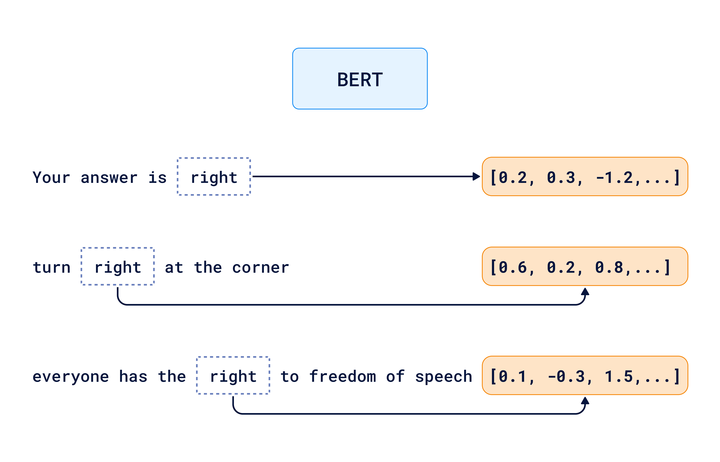
So, how do we help computers grasp the nuances of language in different contexts? In other words, how do we differentiate between:
"your answer is right"
"turn right at the corner"
"everyone has the right to freedom of speech"
Each of these sentences use the word 'right', with different meanings.
More advanced models like BERT and GPT use deep learning models based on the transformer architecture, which helps computers consider the full context of a word. These models pay attention to the entire context. The model understands the specific use of a word in its surroundings, and then creates different embeddings for each.
But how does this process of understanding and interpreting work in practice? Think of the term: "biophilic design", for example. To generate its embedding, the transformer architecture can use the following contexts:
"Biophilic design incorporates natural elements into architectural planning."
"Offices with biophilic design elements report higher employee well-being."
"...plant life, natural light, and water features are key aspects of biophilic design."
And then it compares contexts to known architectural and design principles:
"Sustainable designs prioritize environmental harmony."
"Ergonomic spaces enhance user comfort and health."
The model creates a vector embedding for "biophilic design" that encapsulates the concept of integrating natural elements into man-made environments. Augmented with attributes that highlight the correlation between this integration and its positive impact on health, well-being, and environmental sustainability.
Integration with Embedding APIs
Selecting the right embedding model for your use case is crucial to your application performance. Qdrant makes it easier by offering seamless integration with the best selection of embedding APIs, including Cohere, Gemini, Jina Embeddings, OpenAI, Aleph Alpha, Fastembed, and AWS Bedrock.
If you’re looking for NLP and rapid prototyping, including language translation, question-answering, and text generation, OpenAI is a great choice. Gemini is ideal for image search, duplicate detection, and clustering tasks.
Fastembed, which we’ll use on the example below, is designed for efficiency and speed, great for applications needing low-latency responses, such as autocomplete and instant content recommendations.
We plan to go deeper into selecting the best model based on performance, cost, integration ease, and scalability in a future post.
Create a Neural Search Service with Fastembed
Now that you’re familiar with the core concepts around vector embeddings, how about start building your own Neural Search Service?
Tutorial guides you through a practical application of how to use Qdrant for document management based on descriptions of companies from startups-list.com. From embedding data, integrating it with Qdrant's vector database, constructing a search API, and finally deploying your solution with FastAPI.
Check out what the final version of this project looks like on the live online demo.
Let me know what you’re building with embeddings. Join Qdrant's Discord community and share your projects!



